Intelligent Transformation with EAI
 Enterprise Application Integration (EAI) has evolved from a simple architecture of connectors that mostly support point-to-point integration scenarios to today’s sophisticated middleware platforms that manage the integration of enterprise applications in numerous ways. With the advent of cloud applications and the need to integrate them into the enterprise ecosystem, the development of robust integration solutions is more relevant than ever before.
Enterprise Application Integration (EAI) has evolved from a simple architecture of connectors that mostly support point-to-point integration scenarios to today’s sophisticated middleware platforms that manage the integration of enterprise applications in numerous ways. With the advent of cloud applications and the need to integrate them into the enterprise ecosystem, the development of robust integration solutions is more relevant than ever before.
Middleware solutions provide four basic functionalities:
- Connectivity to the enterprise applications through a set of standard adapters such as JMS, JDBC, HTTP, REST, SOAP, and various business application adapters for EDI, xBRL RosettaNet, and PIDX.
- Transportation mechanisms that support message- and context-based routing.
- Transformation capabilities to translate various import-type structure formats into the expected output structures.
- Orchestration capabilities to orchestrate the execution of these integrations aligned with the respective business processes they support.
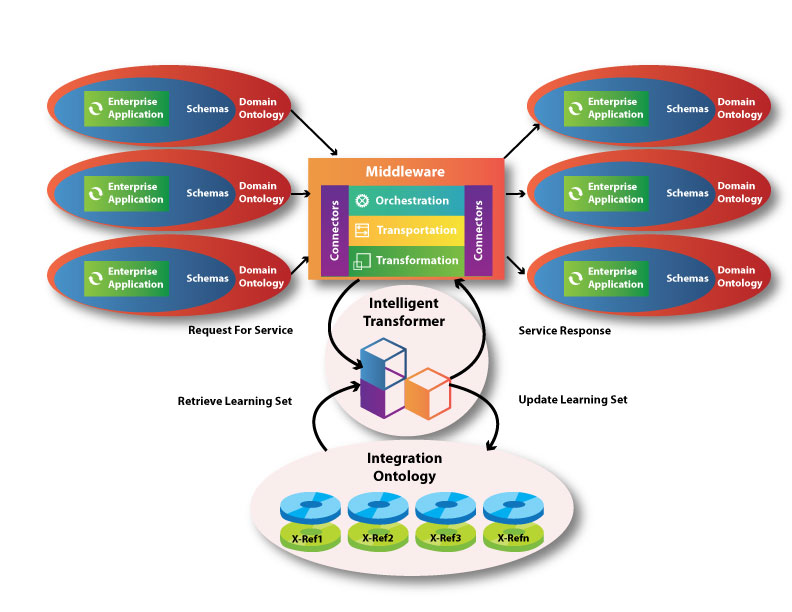
During the evolutionary years of middleware solutions, much attention was given to transportation and translation capabilities. This resulted in extension of functionality of the adapter suites as well as improved routing capabilities. Mapping of structures has been enhanced to allow the integration of custom functions as well as the enrichment of standard provided functions to make it easier to build the required integration.
However, one area that is still providing significant challenges is the transformation of data values from a source application to the respective target application. Normally this data is considered reference data.
The problem of transformation is that these transformation values are stored in cross-reference tables, and the translation functions perform a lookup against these tables to determine from the source value the associated target value. A subsequent problem is the maintainability of these tables. Knowledge of these relationships most often rests with the business users and not the IT department. It is therefore necessary to provide the business users access to these tables so that these tables stay current. This again requires that users be provided with an easy-to-use front-end, which in many cases needs to be developed and maintained.
Inaccurate content of cross-reference tables has a direct impact on the enterprise to deliver value and is a hard cost to the enterprise. Any failed transactions based on invalid or incomplete reference associations will fail and therefore incur a direct cost to the enterprise.
Research Problem
The objective of this project is to research AI capabilities to develop a solution that could minimize or eliminate the manual maintenance process in favour of the AI module (Intelligent Transformer Figure 1), which would use learning sets to discover associations between data values.
- Reducing the cost of failed transactions
- Reducing business user engagement with training and maintenance times
- Providing a full integration to all MDM data for enterprise mapping of data values
- Establishing a homogenous data plain by still allowing best-of-breed architecture strategies.
Research Approach
The research project will be conducted over an estimated 3–4 years and will apply the Design Science Research (DSR) methodology [2]. The main idea of DSR is to solve problems by developing the necessary deliverables in their natural settings as a backdrop. The advantage of the deliverables being aligned with their environments is a higher level of usefulness and acceptance. In addition, this environment provides a good platform of acceptance for the usefulness. DSR has three distinct cycles that interact with each other iteratively to produce design artifacts as the outcome [1,3].
1. Relevance CycleThe relevance cycle is concerned with defining the problem, identifying potential opportunities for the research project, and defining the artifacts for the outcome.
2. Rigor CycleThe rigor cycle focuses on the knowledge base via literature review, expert interviews, and general experience.
3. Design CycleThe input from the relevance cycle and the rigor cycle provides the input to the design cycle for developing the artifacts as the ultimate outcome. The results can be validated through field testing and case studies. The final step is the communication of the results.
References
[1] evner, A. R. (2007). A three cycle view of design science research. Scandinavian Journal of Information Systems, 19(2), 87–92.
[2] Hevner, A. & Chatterjee, S..(2010). Design research in information systems: Theory and practice. New York: Springer.
[3] Offermann, P., Levina, O., Schönherr, M., & Bub, U. (2009, May). Outline of a design science research process. In Proceedings of the 4th International Conference on Design Science Research in Information Systems and Technology, 7. Retrieved from ACM Digital Library.